
What is Azure Synapse Analytics (formerly SQL DW)?
Azure Synapse is an analytics service that brings together enterprise data warehousing and Big Data analytics. It gives you the freedom to query data on your terms, using either serverless on-demand or provisioned resources—at scale.
Azure Synapse has four components:
- Synapse SQL: Complete T-SQL based analytics –
Generally Available •SQL pool (pay per DWU provisioned) •SQL on-demand (pay per TB processed)
- Spark: Deeply integrated Apache Spark
- Synapse Pipelines: Hybrid data integration •Studio: Unified user experience.
Key component of a big data solution

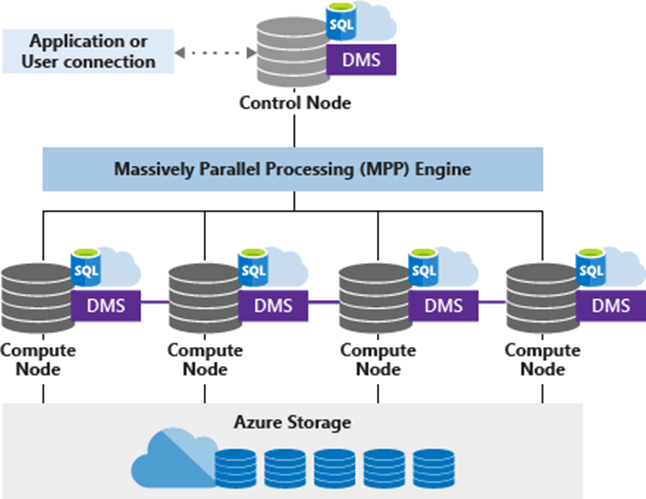
Synapse SQL MPP architecture components:
Synapse SQL leverages a scale-out architecture to distribute computational processing of data across multiple nodes. The unit of scale is an abstraction of compute power that is known as a data warehouse unit. Compute is separate from storage, which enables you to scale compute independently of the data in your system.
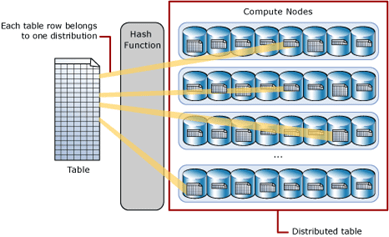
Distributions:
Hash-distributed tables: A hash-distributed table distributes table rows across the Compute nodes by using a deterministic hash function to assign each row to one distribution.
Round-robin distributed tables: A round-robin distributed table distributes table rows evenly across all distributions. The assignment of rows to distributions is random. Unlike hash-distributed tables, rows with equal values are not guaranteed to be assigned to the same distribution.
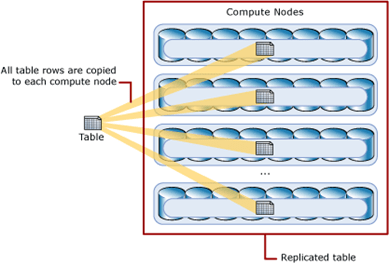
Replicated Tables:
A replicated table provides the fastest query performance for small tables. A table that is replicated caches a full copy of the table on each compute node. Consequently, replicating a table removes the need to transfer data among compute nodes before a join or aggregation. Replicated tables are best utilized with small tables.
Data Warehouse Units (DWUs):
- A Synapse SQL pool represents a collection of analytic resources that are being provisioned. Analytic resources are defined as a combination of CPU, memory, and IO.
- These three resources are bundled into units of compute scale called Data Warehouse Units (DWUs). A DWU represents an abstract, normalized measure of compute resources and performance.
How many data warehouse units do I need:
Steps for finding the best DWU for your workload:
1.Begin by selecting a smaller DWU.
2.Monitor your application performance as you test data loads into the system, observing the number of DWUs selected compared to the performance you observe.
3.Identify any additional requirements for periodic periods of peak activity. Workloads that show significant peaks and troughs in activity may need to be scaled frequently.
Best practices for Synapse SQL pool in Azure Synapse Analytics:
- Group INSERT statements into batches
- Use PolyBase to load and export data quickly
- Load then query external tables
- Hash distribute large tables ±Do not over-partition
- Minimize transaction sizes
- Reduce query result sizes
- Use the smallest possible column size
- Use temporary heap tables for transient data
- Optimize clustered columnstore tables ±Use larger resource class to improve query performance

Leave a comment